

Drupal Development made easier with Qt Assistant - Part 3b
Remember when last time we fixed Doxygen comments of Drupal so they would look right even when using Doxygen? It's time for another part in the series, and we'll continue with some more fixing. Do you still need to get set up, because perhaps you missed the earlier parts? Please (re)read parts 1, 2 and especially 3a before you move on. This time: getting in-depth topics such as the Forms API working as expected. Let's go!
The problem
In the Drupal documentation comments, all links, including the ones to other pages, are set using the @link command. We already fixed external and Drupal specific links earlier. However, our Doxygen documentation still doesn't contain some topics as Doxygen doesn't just process or include HTML files. Because of the Doxygen processing, the defined links also remain without valid target. The links don't work, and we don't have the nice documentation together with the rest.
We could of course just change the links to the external pages at api.drupal.org. But wouldn't it be nicer to have the documentation all in one place? That's what we're going to achieve right now!
More preprocessing
Remember how in our preprocessor we left some extra space for HTML preprocessing? We'll now create a HtmlPreprocessor. Later on we'll let Doxygen scan HTML files as well. And with our special preprocessor, we will trick Doxygen to create and include the HTML pages, which we can link to without even changing the existing links.
First some structure. Open up the preprocess-drupal-doxygen.php file in your text editor or IDE again. Below the CodePreprocessor class, add the following skeleton:
class HtmlPreprocessor extends Preprocessor {
private $_basename = ''; /**< The basename of the filename */
public function __construct ($filename) {
Preprocessor::__construct($filename);
$this->_basename = basename($filename);
}protected function doProcess($contents) {
// We will go and fill this in soon...}}
I've already created the constructor for you, which stores the basename of the file we're processing (that's the filename without path or directories). We'll need it later. The doProcess() function is also in place, but is in need of some content.
Remember that the $contents variable will store the entire HTML file. This may include headers, closing garbage and much more. But for future convenience, or perhaps for your own projects, perhaps you just want to create a simple HTML page with only content. The file itself will then not be valid HTML, but when put inside Doxygen output, everything will be just fine. Whatever the input is, we'll deal with it as good as we can.
Grabbing the title
The first part of the doProcess will deal with extracting the title from the document. The preferred title will be enclosed in a <title> tag. But if we get no header, we may want to check some other tags like <h1> through <h6>. For each of these, we check the document if the tag exists and has some content. We'll then grab the contents of the tag and make sure it is all on one line. If the document happens to contain a line break in the middle of the contents, we don't want that to break our documentation.
Finally, if none of the tags are found, we fall back to using the file's name. This gives us the following code, of which the regular expression is inspired by the Drupal API module:
// Find title in the first listed tag that's in the file$title = NULL;
$titleTags = array('title', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6');
foreach($titleTags as $tag) {
$titleMatch = array();
if (preg_match('@<' . $tag . '(\s.*?)?>\s*(\w.*?)\s*</' . $tag . '\s*?>@is', $contents, $titleMatch)) {
$title = str_replace("\n", " ", $titleMatch[2]); // Make sure it's all on one line
break;
}}if (!isset($title)) {
$title = $this->_basename;
}
And the body?
Next is the actual contents. We have two cases to deal with, as described before: one if the file contains a full HTML page (including header and whatnot, and the all-important <body> tag), or one which is a bit messy and has only the actual content (without a <body> tag).
So what do we do? Like the method used above, we go and grab the contents of the <body> tag. If our regular expression doesn't match, we'll just use the entire file:
// Get <body> of HTML, if present (otherwise use whole document)$bodyMatch = array();
if (preg_match('!<body(\s.*?)?>(.*)</body(\s.*?)?>!is', $contents, $bodyMatch)) {
$contents = $bodyMatch[2];
}$contents = str_replace("\n", "\n * ", $contents);
$contents = preg_replace('!([@\\\\])endhtmlonly!', '\\1<span>endhtmlonly</span>', $contents);
The last but one line indents every line with " * ". Doxygen will remove this indentation from output again. So why do we do this? Just in case the HTML document starts a line with " * " somewhere, we want to keep that in the output. By adding the indentation in our preprocessor, Doxygen will remove only what we added, and nothing else.
Another issue is that the document may contain the Doxygen @endhtmlonly command in the content. As you'll see later, this may cause breakage, as that will terminate our @htmlonly block, used to insert the HTML code verbatim below. Note that in such a block, @endhtmlonly is also the only Doxygen command that is recognized, with escaping it being of no use at all. So we simply break the command wherever it occurs, by placing the endhtmlonly part in an (otherwise useless) <span> tag. You won't see the difference, but Doxygen will see @<span>endhtmlonly</span> and stick to printing verbatim HTML code. Success!
Finally, we may have some cross references in between documents. For example, the Forms API Quickstart and Forms API Reference refer to each other, using absolute links to api.drupal.org. That works, but as we have all that documentation in Doxygen, again, why not let everything work from the same place?
So let's replace some links. Add a new function to the HtmlPreprocessor:
private function replaceLinks($contents, $links) {
foreach($links as $original => $new) {
$re = '/(<a\s+[^>]*)href=(["\'])' . str_replace('/', '\/', $original) . '(\/\S*)?\\2/si';
$contents = preg_replace($re, '\\1href=\\2' . $new . '\\2', $contents);
}return $contents;
}
This function will find links we pass into the $links array (as keys), and replace them with their values. It will also catch longer URLs, if the given URL is continues with a slash and then some more stuff. As such, a link to http://api.drupal.org/api/file/developer/topics/forms_api_reference.html/6 will turn into just forms_api_reference.html if we call it as follows (add this to the doProcess() function body):
$contents = $this->replaceLinks($contents, array(
'http://api.drupal.org/api/file/developer/topics/forms_api.html' => 'forms_api.html',
'http://api.drupal.org/api/file/developer/topics/forms_api_reference.html' => 'forms_api_reference.html',
'http://api.drupal.org/api/file/developer/topics/javascript_startup_guide.html' => 'javascript_startup_guide.html',
));
Now for the all important step: create the Doxygen comment and include the HTML code. We'll give Doxygen some documentation of the file itself, and create a Doxygen page with some HTML only content. This is easy by just creating an appropriate Doxygen comment block:
$contents = "/**\n"
// Clone page's documentation in File listing. " * @file\n"
. " * @brief @link {$this->_basename} {$title} @endlink\n"
. " * \n"
. " * This file contains a special documentation topic: @link {$this->_basename} {$title} @endlink.\n"
. " */\n"
// Create custom page. "/**\n"
. " * @page {$this->_basename} {$title}\n"
. " * \n"
. " * @htmlonly\n"
. " * " . $contents . "\n"
. " * @endhtmlonly\n"
. " */\n";
return $contents;
There will be one minor issue now. If we go to the files list in the Doxygen output and look up our HTML file there, that part will not contain the actual documentation. It will instead link to the custom page we created, which has everything we want. If you like, you can copy the three lines from @htmlonly to @endhtmlonly to the file's documentation. Unfortunately if you leave out the custom page, the normal links to the page don't seem to work, so that page will need to stay in.
You can now refer to the documentation file anywhere you like by using the Doxygen command @link (e.g. "@link file.html My Link Text @endlink").
There's just one bit left in our preprocessor to do: actually construct and use this new HtmlPreprocessor. If you used the script of the last time, find the line near the end saying // HTML Processing is for later.... Found it? Replace that line with the following:
$processor = new HtmlPreprocessor($filename);
That's all for the preprocessor. Note that if you got lost somewhere in the process, you can download the complete script below. All the code is GPL v2 by the way, so feel free to change, reuse and redistribute it.
But Doxygen still doesn't read HTML files!
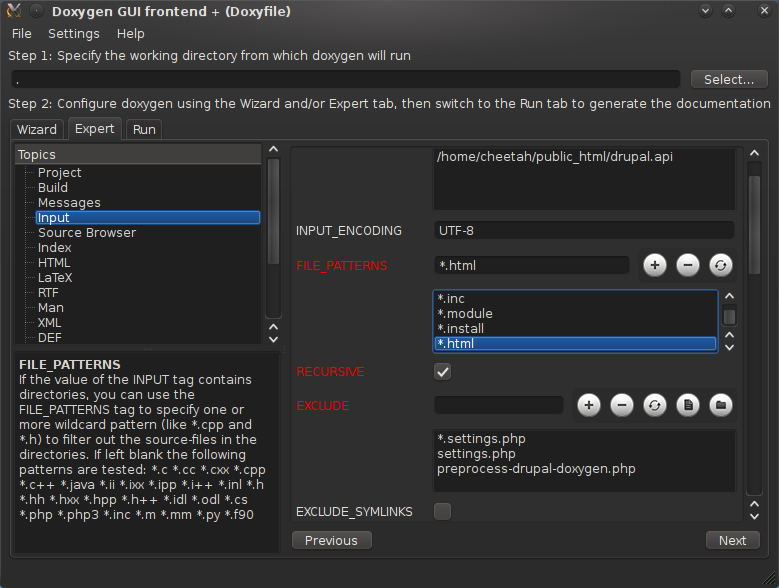
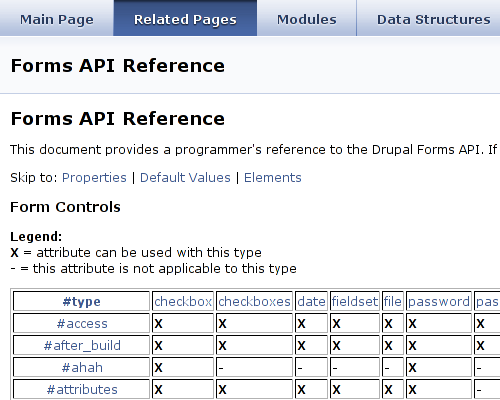
Now the preprocessor is completely in place, we can let Doxygen include our HTML files. This is fairly simple: in the past we let it only handle some .php, .inc, .module and .install files for Drupal. Just add .html (and any other extensions you may use) to the FILE_PATTERNS list (Input topic) in the Doxywizard. Run Doxygen, and the custom documentation will be nicely included. For Drupal documentation, simply check the main page to get to the topics. If all went well, it should all work just fine.
Summary
In part 1 we prepared our system, and in part 2 we got our Drupal documentation in the Qt Assistant. Now we fixed the documentation using some homebrew code from part 3a and this part. Last time we corrected some differences between the commands used by the Drupal API module and Doxygen, making Doxygen output resemble the output of the module. This time we expanded our code to include advanced topics from HTML pages.
There's just one issue left. All the documentation, core and modules, is grouped together. But often it's also nice to view the documentation of just a specific module. Qt Assistant makes this possible by letting it show us a selection of documentation collections (which may be the whole package as we have now). How? I'll be back soon.
Other posts in this series:
| Attachment | Size |
|---|---|
| Doxyfile. | 62.98 KB |
| preprocess-drupal-doxygen.phps | 12.45 KB |
Recent comments
14 years 7 weeks ago
14 years 7 weeks ago
14 years 8 weeks ago
14 years 23 weeks ago
14 years 23 weeks ago
14 years 23 weeks ago
14 years 28 weeks ago
14 years 28 weeks ago
14 years 28 weeks ago
14 years 28 weeks ago